CUDA API Reference (Actual Implementation)
This document describes the actual CUDA implementations in AnalysisG, which use PyTorch tensor operations.
Overview
The CUDA code in AnalysisG is designed to work with PyTorch tensors, not raw arrays. All kernels use:
torch::Tensorfor input/outputtorch::PackedTensorAccessorfor kernel accessAT_DISPATCH_FLOATING_TYPESfor type templatingAutomatic CPU/GPU device handling
Location: src/AnalysisG/pyc/*/ with .cu and .cuh files
Physics Calculations (pyc/physics)
Location: pyc/physics/physics.cu and pyc/physics/include/physics/physics.cuh
The physics module provides kinematic calculations on four-momentum tensors.
Momentum Magnitude
-
torch::Tensor physics_::P2(torch::Tensor *pmc)
Compute squared momentum magnitude P² = px² + py² + pz².
- Parameters:
pmc – Four-momentum tensor [N, 4] with columns [px, py, pz, e]
- Type pmc:
torch::Tensor*
- Returns:
P² tensor [N, 1]
- Rtype:
torch::Tensor
CUDA Kernel:
_P2K<scalar_t, 128><<<blocks, threads>>>Usage:
torch::Tensor pmc = torch::rand({1000, 4}, torch::kCUDA); torch::Tensor p2 = physics_::P2(&pmc); // [1000, 1]
-
torch::Tensor physics_::P(torch::Tensor *pmc)
Compute momentum magnitude P = √(px² + py² + pz²).
- Parameters:
pmc – Four-momentum tensor [N, 4]
- Returns:
P tensor [N, 1]
CUDA Kernel:
_PK<scalar_t, 128><<<blocks, threads>>>
Velocity (Beta)
-
torch::Tensor physics_::Beta2(torch::Tensor *pmc)
Compute β² = P²/E² (squared velocity in natural units).
- Parameters:
pmc – Four-momentum tensor [N, 4]
- Returns:
β² tensor [N, 1]
CUDA Kernel:
_Beta2<scalar_t, 128><<<blocks, threads>>>
-
torch::Tensor physics_::Beta(torch::Tensor *pmc)
Compute β = P/E (velocity in natural units).
- Parameters:
pmc – Four-momentum tensor [N, 4]
- Returns:
β tensor [N, 1]
Invariant Mass
-
torch::Tensor physics_::M2(torch::Tensor *pmc)
Compute squared invariant mass M² = E² - P².
- Parameters:
pmc – Four-momentum tensor [N, 4]
- Returns:
M² tensor [N, 1]
CUDA Kernel:
_M2<scalar_t, 128><<<blocks, threads>>>Example:
// Compute mass of particle combinations torch::Tensor combined_pmc = particle1_pmc + particle2_pmc; torch::Tensor mass_squared = physics_::M2(&combined_pmc); torch::Tensor mass = torch::sqrt(mass_squared); // MeV
-
torch::Tensor physics_::M(torch::Tensor *pmc)
Compute invariant mass M = √(E² - P²).
- Parameters:
pmc – Four-momentum tensor [N, 4]
- Returns:
M tensor [N, 1]
Transverse Mass
-
torch::Tensor physics_::Mt2(torch::Tensor *pmc)
Compute squared transverse mass Mt² = Et² - pt².
- Parameters:
pmc – Four-momentum tensor [N, 4] or [N, 2] with [pz, e]
- Returns:
Mt² tensor [N, 1]
-
torch::Tensor physics_::Mt(torch::Tensor *pmc)
Compute transverse mass Mt = √(Et² - pt²).
- Parameters:
pmc – Four-momentum tensor
- Returns:
Mt tensor [N, 1]
Angular Quantities
-
torch::Tensor physics_::Theta(torch::Tensor *pmc)
Compute polar angle θ = atan2(pt, pz).
- Parameters:
pmc – Four-momentum or momentum tensor [N, 3+]
- Returns:
θ tensor [N, 1] in radians
-
torch::Tensor physics_::DeltaR(torch::Tensor *pmu1, torch::Tensor *pmu2)
Compute angular separation ΔR = √(Δη² + Δφ²).
- Parameters:
pmu1 – First four-momentum tensor [N, 4]
pmu2 – Second four-momentum tensor [N, 4]
- Returns:
ΔR tensor [N, 1]
Usage:
torch::Tensor dr = physics_::DeltaR(&lepton_pmc, &jet_pmc); // Apply DR < 0.4 cut torch::Tensor mask = dr < 0.4;
Overloads: All functions have overloads accepting separate px, py, pz, e tensors.
Mathematical Operators (pyc/operators)
Location: pyc/operators/operators.cu and pyc/operators/include/operators/operators.cuh
Vector Operations
-
torch::Tensor operators_::Dot(torch::Tensor *v1, torch::Tensor *v2)
Compute dot product between vectors.
- Parameters:
v1 – First vector tensor [N, M, K]
v2 – Second vector tensor [N, M, K]
- Returns:
Dot product tensor [N, M, M]
CUDA Kernel:
_dot<scalar_t, 16, 4><<<blocks, threads>>>Threads: dim3(16, 4, 4)
-
torch::Tensor operators_::Cross(torch::Tensor *v1, torch::Tensor *v2)
Compute cross product v1 × v2.
- Parameters:
v1 – First vector tensor [N, M, K, 3]
v2 – Second vector tensor [N, M, 3]
- Returns:
Cross product tensor [N, M, K, 3]
CUDA Kernel:
_cross<scalar_t><<<blocks, threads>>>
Angular Operations
-
torch::Tensor operators_::CosTheta(torch::Tensor *v1, torch::Tensor *v2, unsigned int lm = 0)
Compute cos(θ) between vectors using v1·v2 / (|v1||v2|).
- Parameters:
v1 – First vector [N, M]
v2 – Second vector [N, M]
lm – Optional vector dimension limit
- Returns:
cos(θ) tensor [N, 1]
Optimized Path: For M < 3, uses PyTorch operations instead of CUDA kernel
CUDA Kernel:
_costheta<scalar_t><<<blocks, threads, shared_mem>>>Shared Memory:sizeof(double) * M * 2bytes
-
torch::Tensor operators_::SinTheta(torch::Tensor *v1, torch::Tensor *v2, unsigned int lm = 0)
Compute sin(θ) = √(1 - cos²(θ)).
- Parameters:
v1 – First vector [N, M]
v2 – Second vector [N, M]
- Returns:
sin(θ) tensor [N, 1]
Rotation Matrices
-
torch::Tensor operators_::Rx(torch::Tensor *angle)
Rotation matrix around x-axis.
- Parameters:
angle – Rotation angles [N]
- Returns:
Rotation matrices [N, 3, 3]
CUDA Kernel:
_Rx<scalar_t><<<blocks, threads>>>Threads: dim3(64, 3, 3)
-
torch::Tensor operators_::Ry(torch::Tensor *angle)
Rotation matrix around y-axis.
- Parameters:
angle – Rotation angles [N]
- Returns:
Rotation matrices [N, 3, 3]
-
torch::Tensor operators_::Rz(torch::Tensor *angle)
Rotation matrix around z-axis.
- Parameters:
angle – Rotation angles [N]
- Returns:
Rotation matrices [N, 3, 3]
Graph Operations (pyc/graph)
Location: pyc/graph/pagerank.cu and pyc/graph/include/graph/pagerank.cuh
PageRank Algorithm
-
std::map<std::string, torch::Tensor> graph_::page_rank(torch::Tensor *edge_index, torch::Tensor *edge_scores, double alpha, double threshold, double norm_low, long timeout, int num_cls)
Compute PageRank scores for graph nodes.
- Parameters:
edge_index – Edge connectivity [2, num_edges] with [src, dst] nodes
edge_scores – Edge weights [num_edges, 1]
alpha – Damping factor (typically 0.85)
threshold – Convergence threshold
norm_low – Normalization lower bound
timeout – Maximum iterations
num_cls – Number of clusters
- Type edge_index:
torch::Tensor* (long)
- Type edge_scores:
torch::Tensor* (float)
- Returns:
Map with keys “pagerank” (scores), “clusters” (assignments), “count” (cluster sizes)
CUDA Kernels:
_get_max_node<128><<<blocks, threads>>>- Count outgoing edges per node_get_remapping<<<blocks, threads>>>- Build node remapping_page_rank<scalar_t, 128><<<blocks, threads>>>- Iterative PageRank computation
Algorithm:
Build adjacency structure
Initialize PageRank scores uniformly
Iteratively update: PR(v) = (1-α)/N + α·Σ(PR(u)/outdegree(u))
Cluster nodes based on final scores
Example:
// Graph with 100 nodes, 500 edges torch::Tensor edges = torch::randint(0, 100, {2, 500}, torch::kLong); torch::Tensor scores = torch::rand({500, 1}); auto result = graph_::page_rank(&edges, &scores, 0.85, // alpha 1e-6, // threshold 0.01, // norm_low 100, // max iterations 10); // num clusters torch::Tensor pagerank = result["pagerank"]; // [100, 1] torch::Tensor clusters = result["clusters"]; // [100, 1]
-
std::map<std::string, torch::Tensor> graph_::page_rank_reconstruction(torch::Tensor *edge_index, torch::Tensor *edge_scores, torch::Tensor *pmc, double alpha, double threshold, double norm_low, long timeout, int num_cls)
PageRank with particle four-momentum for physics reconstruction.
- Parameters:
pmc – Particle four-momenta [num_nodes, 4]
- Returns:
PageRank results plus reconstructed objects
Neutrino Reconstruction (pyc/nusol)
Location: pyc/nusol/cuda/*.cu and pyc/nusol/include/nusol/*.cuh
The nusol module implements multiple neutrino reconstruction algorithms on GPU.
Single Neutrino (W → lν)
Files: nu.cu, nusol.cu
Solves for neutrino momentum given:
Lepton four-momentum
Missing transverse momentum (MET)
W boson mass constraint
Method: Solves quadratic equation for neutrino pz:
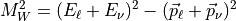
Results in 0, 1, or 2 solutions depending on discriminant.
Double Neutrino (ttbar → WbWb → lνblνb)
Files: nunu.cu, intersection.cu
Solves for two neutrino momenta in dileptonic top pair events.
Constraints:
Two W mass constraints
Two top mass constraints
MET constraint
Method: Numerical optimization to find intersection of constraint surfaces.
Matrix Operations
File: matrix.cu
Matrix utilities for neutrino solving:
Matrix inversion
Determinant calculation
Linear system solving
Coordinate Transforms (pyc/transform)
Location: pyc/transform/transform.cu
The transform module handles coordinate system conversions.
-
torch::Tensor transform_::PxPyPzE2PtEtaPhiE(torch::Tensor *pmc)
Convert Cartesian to cylindrical coordinates.
- Parameters:
pmc – [px, py, pz, e] tensor [N, 4]
- Returns:
[pt, eta, phi, e] tensor [N, 4]
Formulas:
pt = √(px² + py²)
φ = atan2(py, px)
θ = atan2(pt, pz)
η = -ln(tan(θ/2))
-
torch::Tensor transform_::PtEtaPhiE2PxPyPzE(torch::Tensor *pmc)
Convert cylindrical to Cartesian coordinates.
- Parameters:
pmc – [pt, eta, phi, e] tensor [N, 4]
- Returns:
[px, py, pz, e] tensor [N, 4]
Atomic Operations (pyc/cutils)
Location: pyc/cutils/atomic.cu
The cutils module provides atomic operations for CUDA, but the actual implementation is minimal (single include line).
The atomic operations are likely defined in headers:
include/utils/atomic.cuhUsed by other kernels for thread-safe operations
Build Configuration
CUDA Thread Configuration
Typical patterns in AnalysisG:
// Physics operations: 128 threads per block
#define phys_th 128
const unsigned int thx = (dx >= phys_th) ? phys_th : dx;
const dim3 threads = dim3(thx, 3); // 3 for x,y,z components
const dim3 blocks = blk_(dx, thx, 3, 3); // Helper computes blocks
// Operators: 16x4x4 threads
#define op_thread 16
const dim3 threads = dim3(op_thread, 4, 4);
const dim3 blocks = blk_(dx, op_thread, 4, 4, 4, 4);
// Graph operations: Large shared memory
const dim3 threads = dim3(1, dy);
unsigned int shared_mem_size = sizeof(double) * dy * 2;
kernel<<<blocks, threads, shared_mem_size>>>(...);
Type Dispatching
All kernels use PyTorch’s type dispatching:
AT_DISPATCH_FLOATING_TYPES(tensor->scalar_type(), "kernel_name", [&]{
_kernel<scalar_t><<<blocks, threads>>>(...);
});
This generates specialized versions for float and double.
Device Placement
Operations automatically use the device of input tensors:
torch::Tensor out = torch::zeros({N, M}, MakeOp(input));
// out is on same device as input (CPU or CUDA)
Building
CUDA code is compiled during package installation:
pip install -e .
Requirements:
CUDA Toolkit 11.0+
PyTorch with CUDA support
C++14 or later compiler
CMake Configuration: Each module has CMakeLists.txt specifying CUDA compilation.
See Also
C++ Modules API Reference: C++ modules documentation
../pyc/overview: PyC package overview
PyTorch CUDA documentation: https://pytorch.org/docs/stable/notes/cuda.html